
This is an exploration of the code. The README is actually the best “implement in your project” entry point.
This was originally published here on Medium.
I find myself running into Paul Schoenfelder’s (aka Bitwalker’s) libcluster library more and more these days.
The first time was when we wanted to push an elixir app into a custom microservice deployment of mostly Docker containers running Golang services.
Most recently I needed it for an application we deployed via releases to Gigalixir, which uses Kubernetes behind the scenes.
Why did I want to post a dive into libcluster? Because it’s been a breeze to implement each time and it just works.
That’s the kind of software worth learning from.
The Problem
One of the awesome features of Elixir (via Erlang) is that distribution is pretty much baked-in at all levels. It’s a first principle approach to fault-tolerance. If a computer decides to party like its Katy Perry and be a fiiirrrreeeewooorrrk, a fault-tolerant software system should continue to run on computers far, far away from said party.

You can achieve the separate-physical-machine piece of distribution by running different nodes which are separate instances of the Erlang VM¹.
Nodes on separate machines can connect and communicate to each other over a variety of protocols, the default of which is TCP/IP sockets. This means we can use the interwebs to talk to nodes in different physical locations.
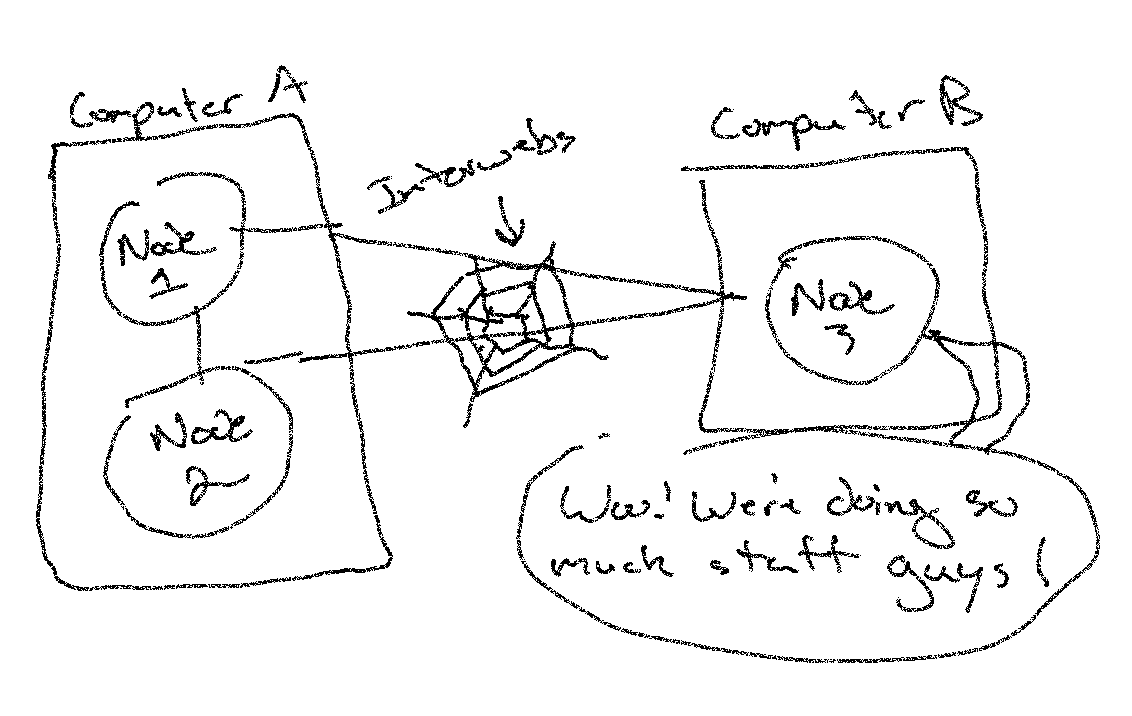
Once we’ve distributed nodes, we’ve seriously increased our fault tolerance. A specific node can go down (whether a runtime crash, OS issue, machine gets unplugged, you name it) and our application will keep plugging away.
That’s not necessarily enough though. That keeps us safe when one computer blows up. But over time we know the probability p of any computer c to spontaneously combust increases exponentially, as given by the Joey Rosztoczy Law of Computational Dynamics™️:
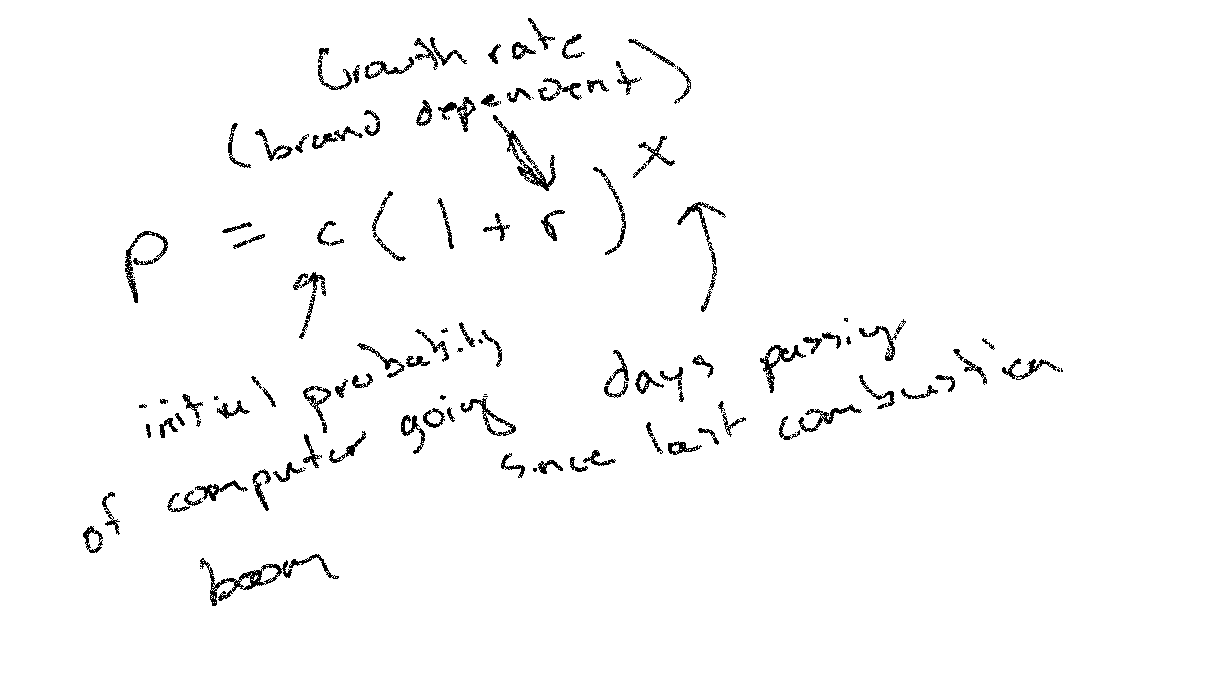
This presents a problem. We don’t want to be left with just one node if Computer A goes down, because we already know its highly likely that our computers will continue to go 💥.
A properly distributed system needs to know how to manage a set of nodes regardless of our spontaneously combusting computers (SCCs). We can then invent tactics to insure virtually no number of lost computers will effect our system’s performance! Let’s call this group of nodes a cluster.
To stay ahead of our SCC’s, we need to know — what nodes are currently in the cluster? We also need to be able to “heal” the cluster — by connecting new nodes that have been spun up and pruning dead nodes. And finally, while the Erlang runtime can manage a lot of these things itself, a lot of other technologies want to distribute across the interwebs², so we’ll need a way to conform to the clustering strategy of our specific environment (like kubernetes).
Enter Libcluster
At the highest level, libcluster enables solving each of these problems. It (1) provides a pub/sub mechanism to keep track of members joining and leaving the cluster, (2) provides pluggable strategies that describe how to execute the clustering and (3) automates “healing” within the clusters.
The kubernetes strategy is an interesting place to start, because kubernetes is essentially mega-cluster-management with similar features (discovery, self-healing, etc) for clusters of containers, with any program you can shove into them. But the Erlang runtime (without any configuration or additional work) can’t know how to escape a particular kubernetes pod and go find all the other nodes isolated in other pods/containers etc. So for our independent Elixir nodes to form a cluster from inside of kubernetes, we’ll need to provide some help.
But enough of the conceptual stuff, let’s jump into the code³! The README and documentation are pretty good. They cover the features of the library and provide a mini “getting started” tutorial. But since we’ve all already read that, we can skip to opening the lib/ directory and scanning the module names on Elixir projects.
It looks like there’s a general “strategy” module / behavior, and then a bunch of modules defining implementations for these strategies, like kubernetes.
Diving straight in to the kubernetes.ex file is a good place to start. Jumping to the middle will give us some clues on how to bridge the theory in the code (which is down a level, in the strategy.ex behavior), with how the strategy gets configured and booted (which is up a level in the supervisor.ex).
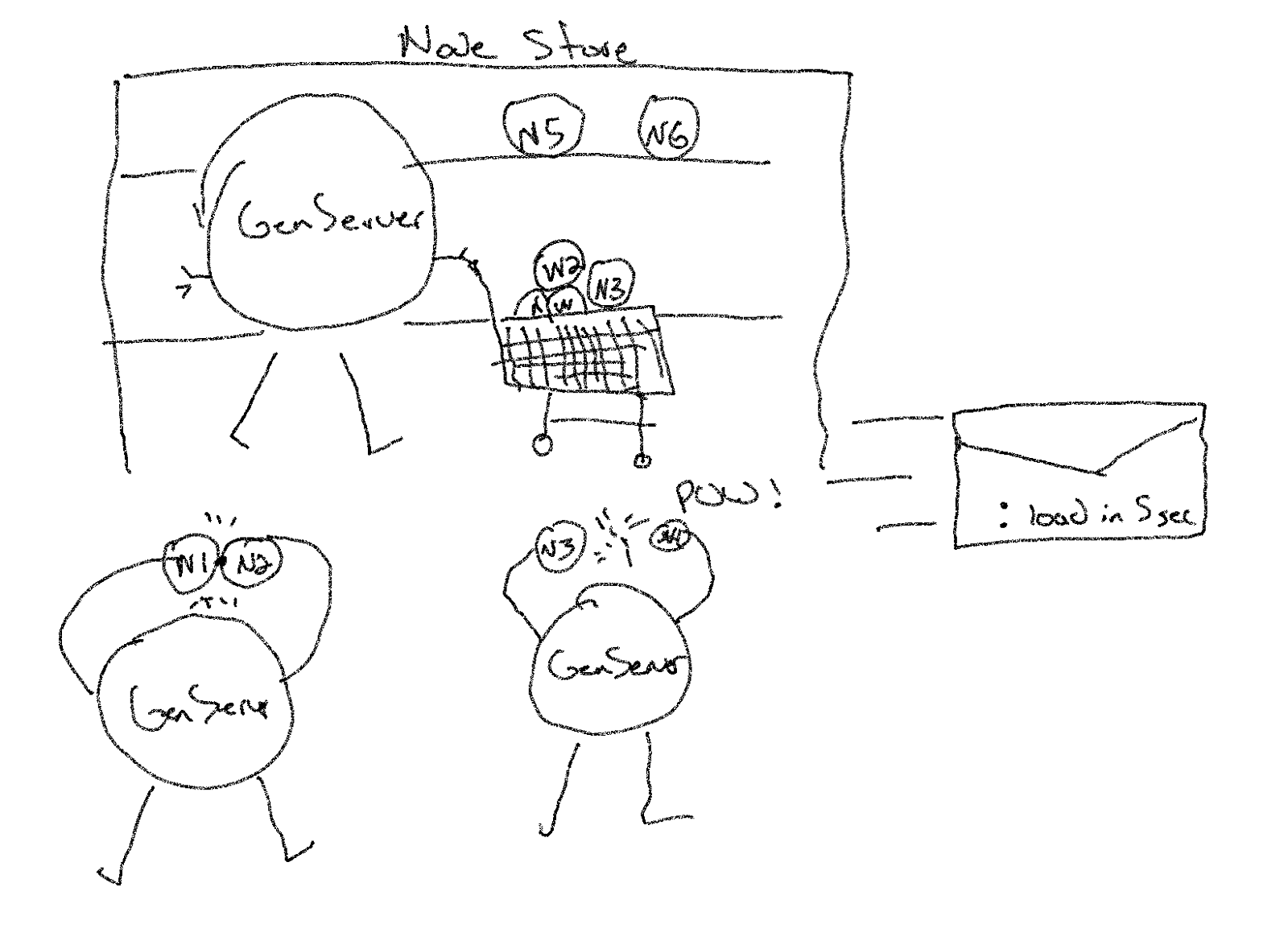
Kubernetes.ex defines a GenServer. The GenServer keeps track of the list of nodes in the cluster in its state. When the GenServer boots it calls load/2. To load the nodes into state, it performs 4ish actions:
- Get’s the nodes currently in the k8s cluster (source of truth for this strategy).
- Disconnects any nodes that are no longer supposed to be connected.
- Connects any new nodes that should be in the cluster but aren’t yet.
- Sends a message to itself to re-evaluate the cluster on some time interval.
Or, in “other words” Kubernetes.load/2 is doing this stuff:
Let’s dig into the first step — getting the current nodes in the cluster. This is going to be necessarily strategy-dependent. We can get the gist from this stunningly rendered annotation provided by yours truly:

Okay, so we got the available nodes running in k8s by making an API call that queried across some of the meta data available in our k8s implementation.
The second and third steps are disconnecting and connecting the right nodes. To find out what’s going on there, we need to head to the Behavior itself, strategy.ex.
The function signature’s are pretty similar for both the connect and disconnect functions. They take a topology, a {module, function, argument} tuple to describe how to connect to nodes, a {module, function, argument} tuple to describe how to retrieve a list of currently connected nodes, and finally a list of nodes that we need to disconnect from the cluster, if they’re currently connected.
The apply(mfa) tuple strategy is used so that libcluster can be extended to support projects that don’t use “normal” distributed Erlang. In those cases you can prescribe custom mechanisms in the config file. But all we care about is the standard Erlang strategy, which is included by default when the supervisor boots in the connect/disconnect/list_nodes mfa’s:
At this point, we can see that we’re getting both the cluster of nodes that exists in kubernetes via our private get_nodes/1 and the list of nodes that our erlang runtime is currently connected to, via our mfa tuple or :erlang.nodes/1. In this strategy k8s is our source of truth. This gives us a node diff, and we can instruct Erlang to remove any nodes currently connected that shouldn’t be, and to establish a connection to new nodes.
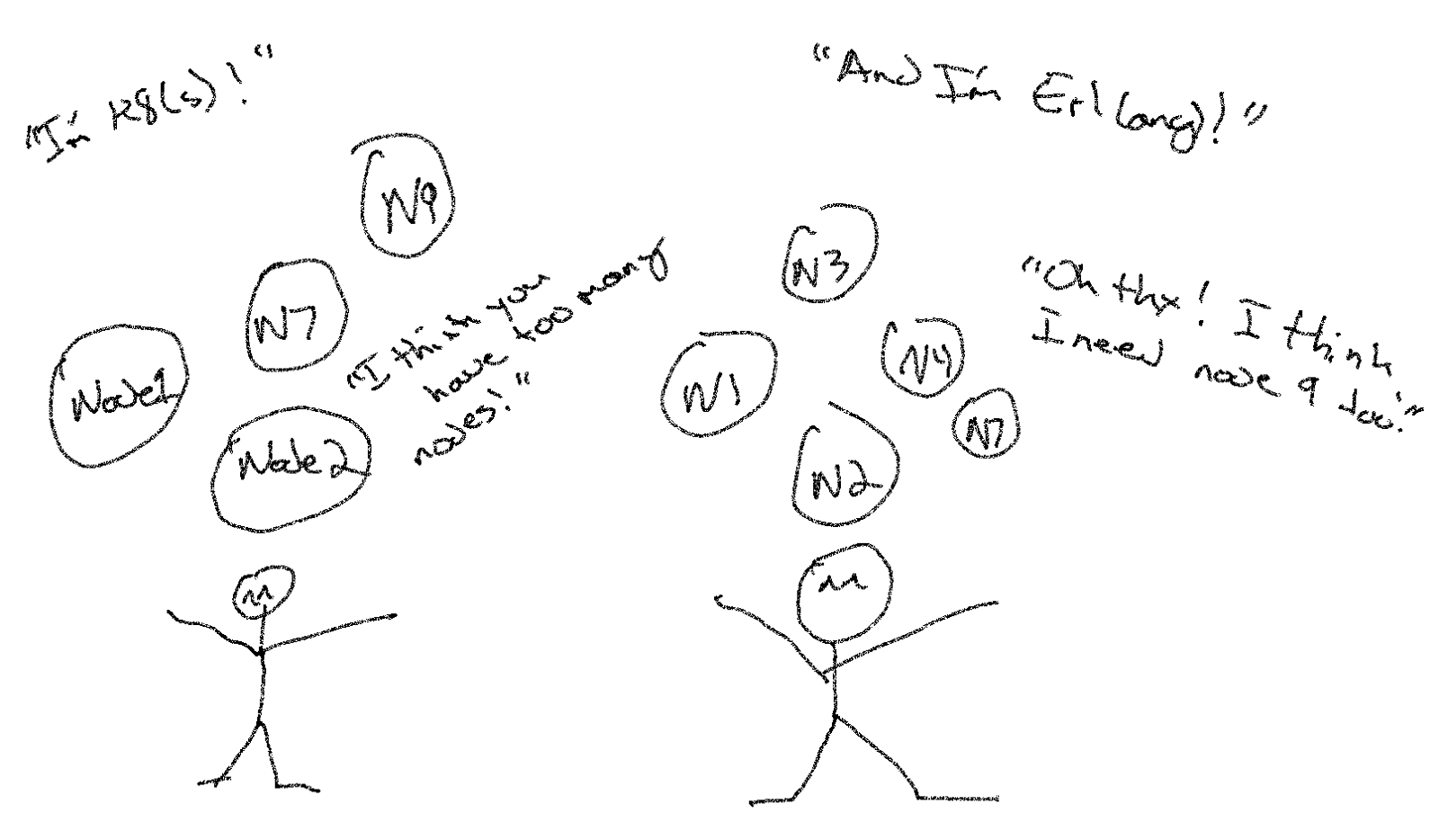
This is the Magic
This sequence, and the fact that its repeated every X milliseconds, is the magic between the “self-healing” features of libcluster. We look up the nodes that should be in the cluster, then prune dead nodes that are no longer in the cluster, and establish connections to the new nodes that should be.
It’s worth noting that distributed Erlang by itself is capable of maintaining its node-list via the Erlang Port Mapper Daemon, and handles nodes that go down naturally in the runtime. In fact the only thing that’s implemented in the epmd.ex strategy is the very initial cluster connection, based on the config file. The rest is left to Erlang ❤.
Thanks for staying tuned and (hopefully awake). One thing I learned from this library was the method of using an MFA tuple to let library user’s specify which Module.functions(arguments) are actually used in a module via a config file.
Pretty neat!
¹Awesome tangent, Erlang nodes will basically mock distress signals from missing nodes, so even if a node blows up so catastrophically that it can’t get a warning message out on the network, the network acts like it did.
²This problem isn’t isolated to Erlang. Lot’s and lot’s of people decided that distributing stuff is a great idea and have spent billions reinventing Erlang/OTP into “microservices” [haters gunna hate].
³I love this helpful guide on “how to read”
